Mise à Jour
18.05.2018 : Un résumé d'une ou deux pages décrivant la méthodologie que vous
avez suivie doit accompagner la soumission.
Final Leaderboard
| Rang |
Equipe |
Score |
| 1. | Balikasg | 3.4856 |
| 2. | Terislepacom | 7.2862 |
| 3. | ICSI | 8.5970 |
| 4. | Caoutchouc | 9.4537 |
| 5. | ACNK | 10.4350 |
| 6. | reciTAL team | 11.2112 |
| 7. | TAU | 12.8222 |
| 8. | Capitaine-Ad-Hoc | 14.1696 |
| 9. | Chamlia | 17.5161 |
| 10. | Haralambous + Lenca Team | 17.9774 |
| 11. | MB | 31.6637 |
| 12. | Rufino | 33.4285 |
| 13. | Team UTC | 40.7879 |
| 14. | Limsi | 41.5202 |
Résumé des deux meilleures soumissions
G. Balikas : Predicting the level of non-native English speakers from their
written essays
In this talk I will present my participation in the CAp 2018
data challenge. I will start by describing the components of my system
and I will proceed by detailing the feature extraction and feature
engineering decisions as well as the model selection and validation
steps. I will conclude the presentation with lessons learned from my
participation.
Alexandre Garcia : Une méthode en deux étapes pour la prédiction du niveau d'anglais.
Le niveau d'anglais d'un texte est caractérisé par des marqueurs visibles au niveau du mot (fautes d'orthographe, choix du vocabulaire) et au niveau du texte (longueur des phrases, tournure syntaxique). Le modèle proposé est construit en 2 étape pour (1) exploiter l'information disponible au niveau du mot par l'utilisation d'un modèle adapté à des entrées parcimonieuses en très grande dimension et (2) fusionner cette information avec des descripteurs structurels du texte. Nous présentons les différentes parties du prédicteur ainsi que les représentations des données exploitées par le modèle.
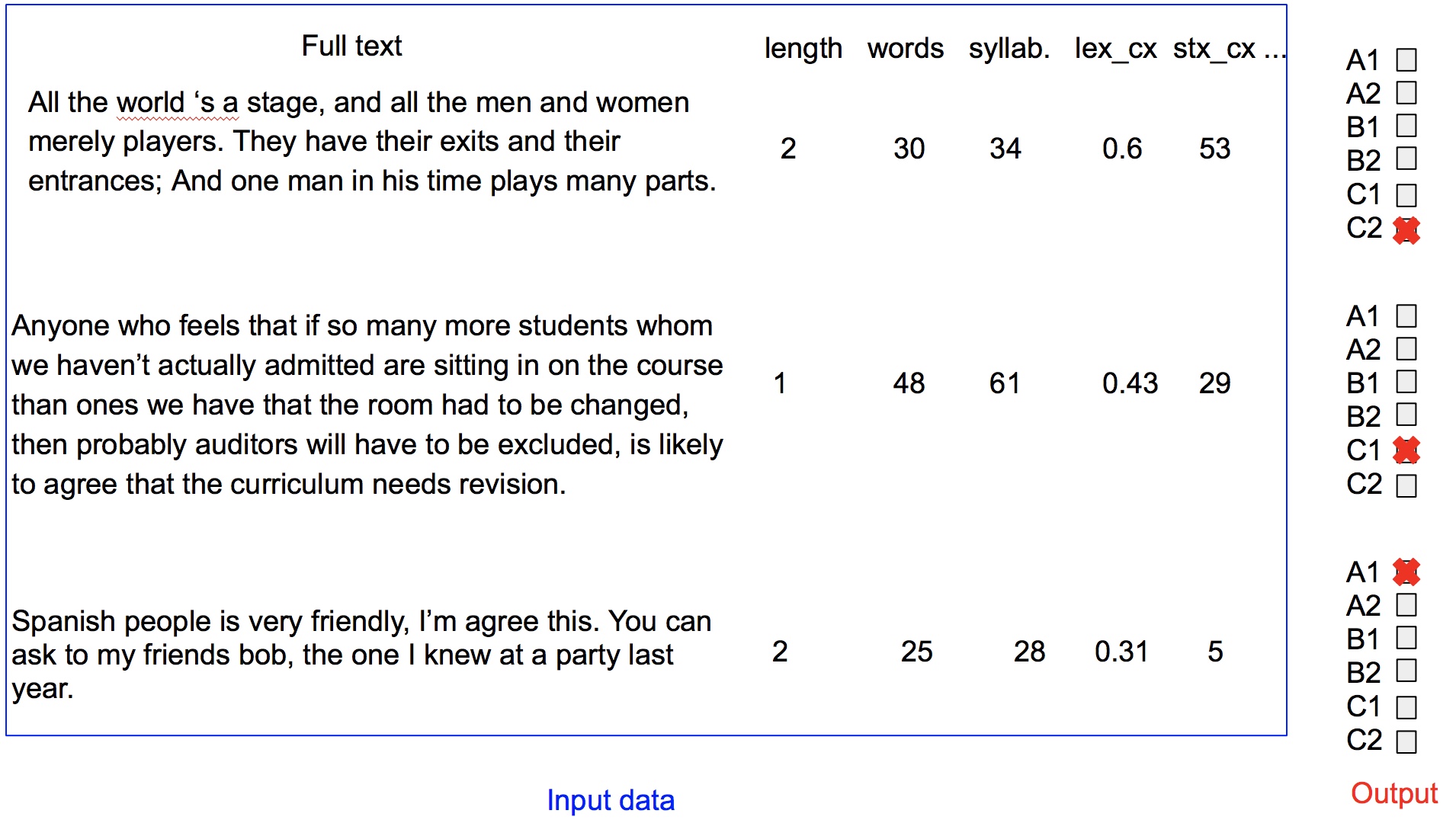
Objectif
Le Cadre européen commun de référence pour les langues (CERL) découpe la
compétence linguistique d’une langue étrangère en six niveaux de référence,
décrits pour être partagés par les pays européens : A1, A2, B1, B2, C1 et C2.
Le but de cette compétition est de réaliser, par apprentissage, un système
permettant de prédire le niveau de compétence d’un apprenant, à partir d’une
de ces productions écrites comprenant entre 20 et 300 mots et d’un ensemble de
caractéristiques calculées à partir de ce texte.
Pour plus de détails.
Pour des informations annexes.
Jeux de données
Pour avoir accès aux données il faut :
vous inscrire ici sur : https://corpus.mml.cam.ac.uk/efcamdat2/public_html/explore/
une fois inscrit, envoyer un email à efcamdat.team@gmail.com avec comme
sujet :
Request for CAp2018 Shared Task Data
Après confirmation de votre inscription, un e-mail avec les informations de connexion
au dossier contenant les données vous sera envoyé dans les 24 heures.
Pour avoir accès aux
données de test il faut :
être inscrit et
envoyer un email à efcamdat.team@gmail.com avec comme sujet : Request for CAp2018 Test Data
Soumission
Pour soumettre vos résultats, envoyez par email un fichier csv avec les valeurs prédites A1, A2...C2 à l'adresse suivante : competition.cap2018@litislab.fr
Dates importantes
La compétition se déroulera sur 2 mois de la manière suivante :
Ouverture de la compétition : 28 mars 2018
Disponibilité du jeu de test : 28 avril 2018
Fin de la compétition : 28 mai 2018 minuit
Annonce des résultats et remise des prix : 21 juin 2018
Prix
NVIDIA attribuera des cartes graphiques GPU 1080Ti aux deux meilleurs systèmes.
Merci à



