Updates
18.05.2018 : a one-or-two-page abstract describing your
methodology for solving the problem has to be jointly submitted
with your scores.
Final Leaderboard
| Rank |
Team |
Score |
| 1. | Balikasg | 3.4856 |
| 2. | Terislepacom | 7.2862 |
| 3. | ICSI | 8.5970 |
| 4. | Caoutchouc | 9.4537 |
| 5. | ACNK | 10.4350 |
| 6. | reciTAL team | 11.2112 |
| 7. | TAU | 12.8222 |
| 8. | Capitaine-Ad-Hoc | 14.1696 |
| 9. | Chamlia | 17.5161 |
| 10. | Haralambous + Lenca Team | 17.9774 |
| 11. | MB | 31.6637 |
| 12. | Rufino | 33.4285 |
| 13. | Team UTC | 40.7879 |
| 14. | Limsi | 41.5202 |
Abstract of the top two submissions
G. Balikas : Predicting the level of non-native English speakers from their
written essays
In this talk I will present my participation in the CAp 2018
data challenge. I will start by describing the components of my system
and I will proceed by detailing the feature extraction and feature
engineering decisions as well as the model selection and validation
steps. I will conclude the presentation with lessons learned from my
participation.
Alexandre Garcia : Une méthode en deux étapes pour la prédiction du niveau d'anglais.
Le niveau d'anglais d'un texte est caractérisé par des marqueurs visibles au niveau du mot (fautes d'orthographe, choix du vocabulaire) et au niveau du texte (longueur des phrases, tournure syntaxique). Le modèle proposé est construit en 2 étape pour (1) exploiter l'information disponible au niveau du mot par l'utilisation d'un modèle adapté à des entrées parcimonieuses en très grande dimension et (2) fusionner cette information avec des descripteurs structurels du texte. Nous présentons les différentes parties du prédicteur ainsi que les représentations des données exploitées par le modèle.
Objectives
The CAp 2018 conference is hosting the following machine learning competition.
The Common European Framework of Reference for Languages (CERL) maps
linguistic competence in a foreign language onto six reference levels, described
to be shared by European countries: A1, A2, B1, B2, C1 and C2.
The goal of this competition is to achieve, by learning, a system to predict
the level of competence of a learner, from one of these written productions
comprising between 20 and 300 words and a set of characteristics calculated
from this text.
For more details.
and supplementary information.
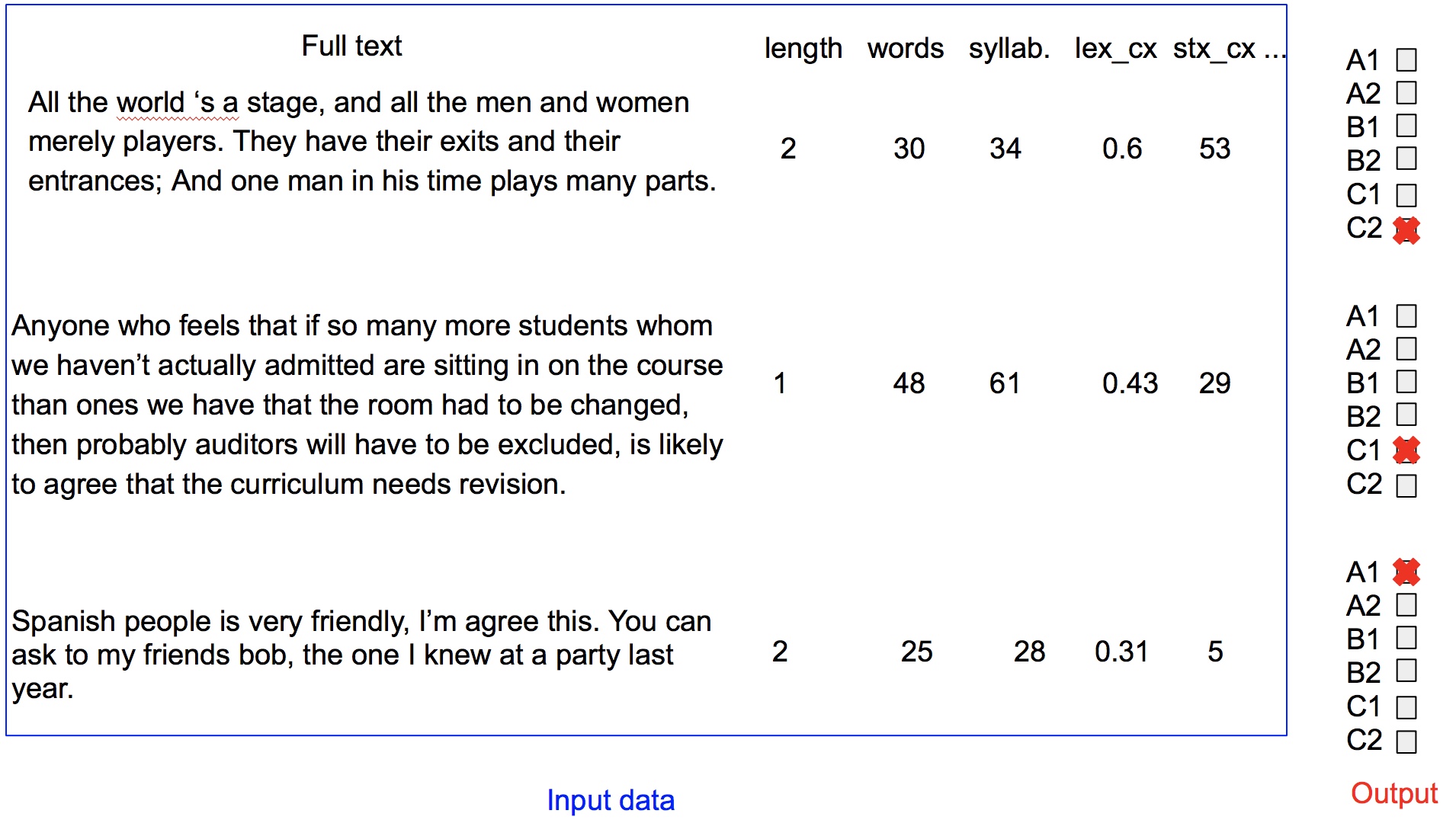
Data set description
To access data competitors have to:
register here to: https://corpus.mml.cam.ac.uk/efcamdat2/public_html/explore/
after registering, the competitors should then send an email to: efcamdat.team@gmail.com with the subject:
Request for CAp2018 Shared Task Data
After we’ve confirmed that you have registered, we will send out an email with
log-in details to the shared task folder within 24 hours.
To have access to
the test data you need to
be registered and
send an email to: efcamdat.team@gmail.com with the subject: Request for CAp2018 Test Data
Submission
To submit your results, email a csv file with the predicted values A1, A2...C2 at competition.cap2018@litislab.fr
Important dates
28 March: call for participation
28 April: release of the test set
28 May : deadline submission
Prizes
NVIDIA will offer a Geforce 1080Ti for each of the top 2 teams.
Thanks to



